Uběhlo dvacet dnů od předchozího testu, kdy jsem chtěl porovnat jak se postaví vyhledávač k duplicitnímu obsahu který byl nejdříve publikován na webu s 404m.com (GPR 4) a druhý den na podnikatel.cz s GPR 6. Samozřejmě i ostatní ranky jsou někde úplně jinde :)
Zatímco v předchozím rychlém testu to naplno vyhrál Google, který se zachoval jak webmástrům slíbil ve většině PR videí, tak Seznam pohořel. Jak tomu ale je po dvaceti dnech, kdy se výsledky tak nějak už zabydlí?
Obsah
Testování
Jako i posledně testujeme výskyt řetězce “Zanedlouho po zrušení Facebook stránky se podělili o zajímavá čísla. EAT24 rozesílá newslettery” což je přesná fráze, která se nachází v samotném článku.
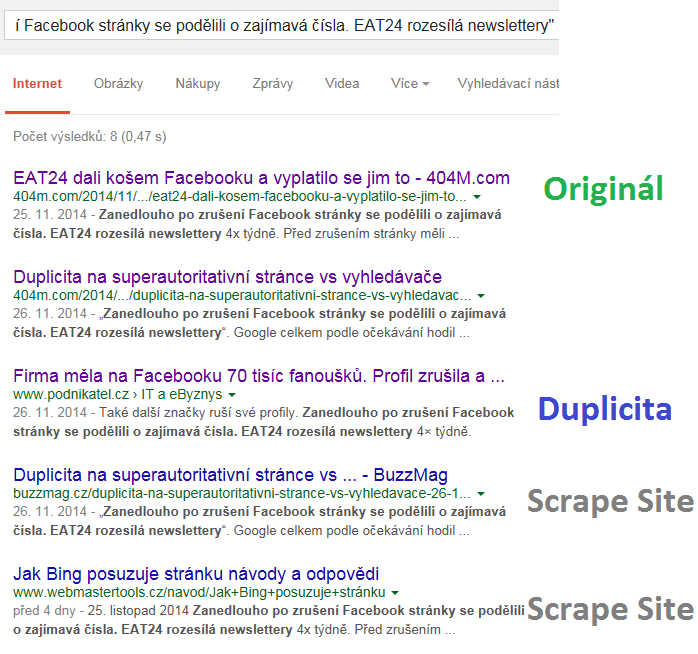
Jak je vidět moc se toho v SERP nezměnilo.
- Originální článek
- Článek posledního testu, nějak jsem na něj zapoměl
- Kopie, či spíše částečně upravený článek
- a 5. jsou scrape site
Výsledek na Google je zajímavý. Zatímco první místo naprosto chápeme, tak u druhého je to zajímavé. Článek byl totiž napsán až po publikování na podnikatel.cz. Tedy pokud by Google postupoval chronologicky, tak by měl být až třetí. Z toho že je na druhém místě se dá vyvodit, ž:
- Buď je v rámci domény originál nějak provázán s případnou kopií (nepenalizuje jí)
- anebo je článek na podnikatel penalizován a nový článek by považován za originální (což je).
Pravděpodobnější mi přijde druhá varianta.
Seznam.cz
Minule jsme museli dát Seznamu jinou část, protože byl v indexaci nějaký pomalejší. Teď už však vše indexuje jak má, takže můžeme srovnat stejné fráze.
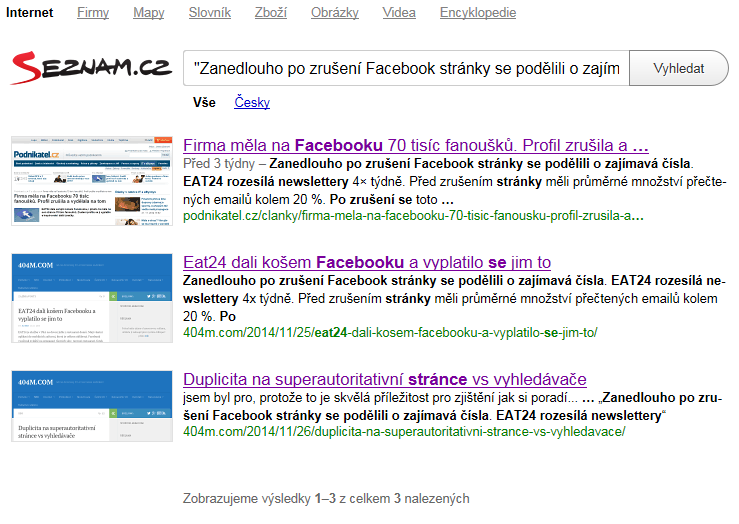
Tak tady vyhrála autorita Podnikatel.cz a z 404M se stala duplicita. Na druhou stranu znovu zmiňuju, že Seznam zaspal s indexací nikoliv algoritmem, ten se k tomu ani nestihl dostat. Výsledkem tedy je, že pokud Seznam nezačne indexovat rychleji, může vás rychleji indexovatelný “vykradač obsahu” předběhnout.
Na druhou stranu zmizelo scrape site z minulého testu, což je pozitivní.
Tak že by nám zafungovali ti brigádníci, co seznam sháněl na Prosinec? No každopádně tenhle výsledek pro něj už vydadá trochu pozitivnějš, než to poslední faux pas. Tak snad ještě něco udělají s tou indexací, ta je dost tristní.
Takže ak to dobre chápem niekto zverejní článok. Ak ten článok hned okopiruje niekto privolá si robota na svoj web nech ho prebehne tak vzhráva ten u koho bol robot prvý to berie ako originál článok? (bavíme sa o GOOGLE)
Lenovo guru: To je reálně možné.
Kvůli možné personalizaci Google, jsem si udělal ten samý test z Hradce Králové z anonymního režimu a Tvé výsledky můžu potvrdit :) Není to tedy tím, že na své stránky chodíš častěji, než na web ponikatel.cz. Hezký test, díky.
Google by nemel brat obsah chronologicky, zvlaste u longtailu. Vem si, ze by nekdo pred 15 lety napsal o pocitacich o taktu 3GHz (tenkrat sci-fi) a dnes by byl v indexu nejvice. Jasne ze Google bere v potaz autoritu domeny, stari domeny a clanku, ale na druhou stranu jsou tak stary informace v dnesni dobe nerelevantni. Druha pozice je urcite zpusobena vetsim opakovanim danych klicovych slov nebo se pozice “dobiji” lepsim umistenim stranky ze stejne domeny.
Hlavně scrape site by se snad podle SEO keců šašků z Google neměl vůbec v serpu objevit. Opak je pravdou, pravidelně se tam vyskytují notoričtí a zcela zjevní lupiči obsahu a nezřídka mají adsense. Že by chybička někde?