Tak po několika týdnech, ladění a testování už mám konečně nějaká data, aby se s nimi dalo pracovat. Poslední relase Aldnoah má 660,4 MB a je postaven ze 1.607.071 URL. Samozřejmě ani zdaleka to není plný potenciál. V současné fázi jsme na 65,88 % klíčových slov a další sbírám ze všech možných i nemožných zdrojů :)
Jdeme se podívat na první zajímavé výsledky. Srovnáme si jaké jak shodné je vyhledávání pro Google a Seznam.
Obsah
Metodika
Prozatím je pro výběr klíčových slov využita hodnota přesné shody na Seznam. Byla zvolena pouze ta klíčová slova, která mají přesnou shodu hledanost 50 a více. Následně bylo z databáze vytaženo kolik shodných URL se nachází do určité pozice. Pro účel testu jsme zvolil stránkování po 10.
- Do testu bylo použito z databáze celkem zhruba 715 tisíc hodnot, které odpovídaly podmínce pozice na Google anebo Seznam a má přesnou shodu 50 a více.
- Procenta jsou vypočítána z maximálního množství společných výsledků na dané úrovni. Tedy součet všech URL na Seznam a Google do určité pozice.
Výsledky
Výsledky jsou znázorněny jako počet průniku hodnot (společné výsledky na daný keyword) a procentem z celkového množství na dané úrovni.
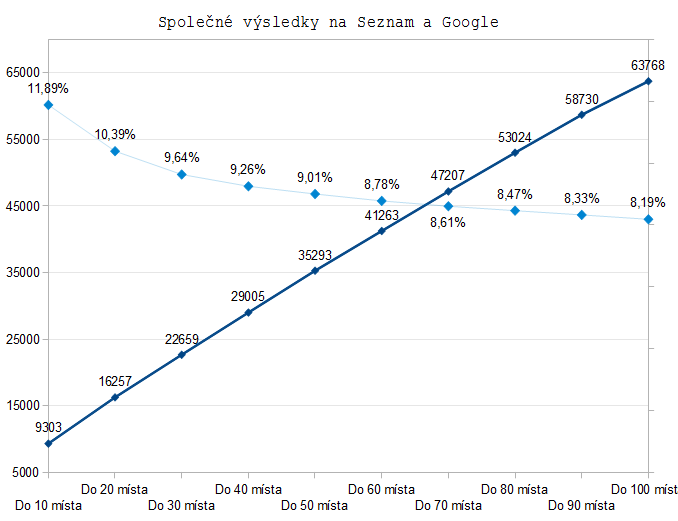
Vysoký počet shod v TOP deset je způsoben hlavně tím, že se tam vyskytují obchodní značky a domény/weby, které lidi zadávají do hledání. Ty mají velkou hledanost. Ačkoliv počet shod roste tím jak hlouběji jdeme, zároveň se více rozchází, protože přibývají nové URL.
Aktualizováno 30.8.2015: Dneska jsem si uvědomil, že výpočet procent je správný, ale neodpovídá na otázku “Jak jsou shodné výsledky na Seznam a Google?” Na rychlo jsem to přepočítal a tady je odpověď:
| Procento shody | |
| Do 10 místa | 23,78% |
| Do 20 místa | 20,79% |
| Do 30 místa | 19,28% |
| Do 40 místa | 18,51% |
| Do 50 místa | 18,01% |
| Do 60 místa | 17,57% |
| Do 70 místa | 17,22% |
| Do 80 místa | 16,94% |
| Do 90 místa | 16,66% |
| Do 100 místa | 16,38% |
Závěr
Všechno je orientační a postaveno na prototypu, který je čerstvě postaven a testován průběžně, takže to tak i berte. Chtěl jsem si vyzkoušet jestli z té databáze dokážu vytáhnout nějaká užitečná data :)
Dále je nutno podotknout, že robot, který prochází Seznam a Google se nacházejí na různých místech ČR. I když jsem se snažil v Google vypnout personalizované/lokální vyhledávání, tak se to nemuselo povést. Dále v některých případech při testování třeba přehozených slov v řetězci anebo s/bez diakritiky mohl jeden vrátit stejné výsledky a druhý nemusel. Tohle bude mít za úkol odhalit jiný test. Sběr dat ze Seznamu byl také proveden o 7 – 14 dnů dříve než ten na Google. I když jsme se zaměřil na hodně hledané keywordy určitě to mohlo ovlivnit výsledky.
ℹ Aldnoah se mi podařilo odladit, takže i přes velké množství dat zatím není nijak extra náročný na databázi. Než překročí 1 GB dat, můžete jej klidně využívat. Najdete jej jako skrytou součást cybersquatting.cz. Budu rád za každou připomínku anebo návrh jak jej vylepšit či rozšířit. Nic není nemožné ;)
Najskôr som myslela že tá zhoda je dosť vysoká ale v podstate nie je a seznam kádže úplne iné výsledky od google. Ale hodne zaujímavý experiment a vyhodnotenie dát, to by niekoho len tak nenapadlo urobiť s datami, takto ich porovnať :)