Canonical je atribut tagu link (příklad: <LINK REL=“canonical“ HREF=“http://LegieStinu.secret“>), který se používá pro označení stránky s originálním obsahem. Jednoduše když dokáže váš skript vygenerovat několik URL se stejným textem, pomocí canonical ukážete vyhledávačům, která stránka je ta pravá a chcete aby jí indexovat. Je to elegantní způsob, jak se vybrat neobratnému přesměrování, noindex a podobným věcem, které vás za určitých okolností mohou dostat do SEO šlamastiky. Jak pracovat s canonical byste měli vědět ať už děláte profesionální anebo sezónní SEO. V znalostní bázi jej má jak Google tak i Seznam.
Přiznám se, že jsem bral Canonical jen jako SEO značku. Prostě když se hrabete v SEO moc dlouho, tak jej vidíte všude. Takže když jsem si dneska přečetl post od Johna Mullera dost mě to zaskočilo. Něco jako WTF? ono se to dá použít i k něčemu jinému než SEO?
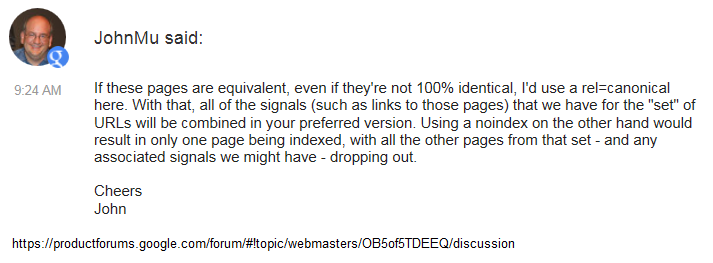
Takže máme tu dvě stránky, které nejsou úplně obsahově identické. Ale ve vyhledávačích bychom rádi viděli jen jednu z toho. To by za určitých okolností mohlo být reálné. Jen mě napadají samé šílenosti :)
V každém případě je dobré vědět, že canonical tu není jen od toho, aby ukazoval která stránka stejného obsahu je originál. Podle Johna se canonical má používat, pokud je stránka ekvivalentem.
Druhá část odpovědi je také zajímavá. Použít noindex na duplicitní stránku je špatná volba. Google totiž stránku, kterou má považovat za duplicitní, stále vyhodnocuje a sleduje u ní signály. Hmm možná proto po odstranění noindex u rubrik a štítku ve WordPress se zvýší počet návštěv z vyhledávačů…
Na tohle téma jsem odpovídal na Twitteru viz: https://twitter.com/SubrJiri/status/611481655065346048
Smutné, že se na konferenci o SEO v roce 2015 doporučuje noindex. Má to spoustu negativních dopadů.